
Un nombre croissant de grandes entreprises se sont mises à l’intelligence artificielle (IA). Des questions se posent sur l’organisation interne, les projets à prioriser et la gouvernance des données. Cela dit, il n’est plus question d’adopter ou pas l’IA, mais plutôt comment.
L’IA : Une intelligence relative et pourtant fort utile
On parle d’Intelligence Artificielle (IA), pourtant les machines sont encore loin d’avoir atteint ce que nous entendons par intelligence. Prenons l’exemple récent de ChatGPT, un excellent modèle de langage qui n’a aucun sens commun et n’est donc pas intelligent. Même si l’IA n’est pas intelligente, cela ne l’empêche pas d’être utile dans une multitude de situations. De nos jours, des modèles d’IA sont utilisés dans tous les secteurs : manufacture, finance, énergie et santé par exemple.
Réservé aux laboratoires de recherche et aux grandes entreprises technologiques il y a quelques années, l’intelligence artificielle est aujourd’hui accessible à toute entreprise. Les facteurs qui ont conduits à un tel épanouissement sont multiples : diminution des coûts de stockage, augmentation de la puissance de calcul et facilité d’utilisation des outils d’IA. Cela dit, pour que les entreprises puissent réussir leur transformation axée sur les données, il faut prendre en compte trois axes complémentaires :
- les cas d’usage,
- les talents,
- un langage commun.
Identifier les cas d’usage pertinents pour votre entreprise
Pour identifier les cas d’usage les plus intéressants, les entreprises peuvent utiliser une approche en trois étapes :
Etape 1 – Identification
Une ou deux sessions de brainstorming avec les parties prenantes sont un excellent point de départ pour lister les idées de cas d’usage. Il faut combiner une approche basée sur les besoins ou envies (top-down) avec une réflexion sur les données à disposition dans l’entreprise (bottom-up).
Etape 2 – Sélection
Les cas d’usage sont placés, de manière approximative, sur une matrice bénéfice / impact. L’objectif étant de les séparer en groupes. De 2 à 5 cas d’usage sont ensuite sélectionnés, pour former un équilibre entre des idées faciles à réaliser tout de suite et des projets prometteurs mais plus complexes.
Etape 3 – Définition
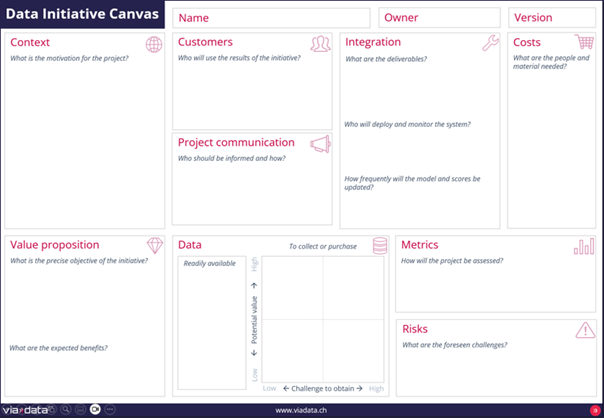
Les cas d’usage sélectionnés sont ensuite détaillés au moyen d’un canevas. En exemple de canevas est fourni ci-dessous (Figure 1 : le Data Initiative Canvas). Le but du canevas est de se poser les bonnes questions sur le projet. Il sert aussi à aligner toutes les parties prenantes sur l’initiative. À noter que le document évoluera au fil du temps.
Pour ces trois étapes, il faut trouver le bon équilibre sur le temps à y consacrer ainsi que les parties prenantes à impliquer pour pouvoir avancer de manière raisonnable.
Trouver les talents adaptés à votre projet d’IA
Pour développer les cas d’usage de l’IA en entreprise, il faut trouver la ou les bons talents. Il y a plusieurs options possibles, comme par exemple :
- La spécialisation des expert·e·s métiers – En effet, l’engagement d’un profil de data scientist est couteux pour une petite entreprise. On peut dès lors former un·e expert·e métier en citoyen·ne de la donnée.
- Le recrutement de data scientists – Si l’entreprise peut se le permettre, il s’agit certainement de la meilleure solution. Le développement de compétences internes est un atout important pour les entreprises sur le long terme.
- Les sociétés de conseils – L’externalisation des ressources est aussi possible. Une étape intermédiaire consiste à recruter un profil de data scientist junior et se faire conseiller par un·e consultant·e sur la stratégie à adopter.
Une fois ce choix effectué, il ne manque plus qu’un ingrédient important pour que l’utilisation de l’IA se fasse à l’échelle de l’entreprise.
Parler le même langage
Pour une utilisation réussie de l’IA en entreprise, il est impératif que les employé·e·s développent un langage commun. C’est d’autant plus critique pour les petites sociétés, qui n’ont souvent pas les moyens d’engager une équipe de data scientists. Pour cela, il faut créer un environnement qui permette à aux employé·e·s de devenir plus autonomes avec les données.
C’est dans ce contexte qu’intervient le concept d’acculturation aux données (data literacy en anglais). Textuellement, cela signifie savoir lire et écrire les données. Plus concrètement, il s’agit de savoir interpréter les données, mais aussi les communiquer. L’idée est que les employé·e·s soient conscient·e·s de l’importance des données, des cas d’applications possibles ainsi que des limites de l’intelligence artificielle.
Une formation pour cadres axée sur la gestion et la valorisation des données
Dans le domaine de la transformation numérique, il est essentiel que les cadres développent une compréhension solide des concepts liés à la Data Science. Une initiative qui répond à ce besoin est le Certificate of Advanced Studies (CAS) en Data Science & Management, élaboré en collaboration par HEC Lausanne et l'EPFL.
Le CAS en Data Science & Management offre un programme unique, conçu spécialement pour les cadres d'entreprise. À la croisée des chemins entre technologie et management, il s’intéresse aux notions telles que :
- Évaluation de la maturité des données en entreprise
- Compréhension et mise en place d'une stratégie efficace pour les données
- Gestion de la gouvernance et de la qualité des données
- Maîtrise de la visualisation des données et conception de tableaux de bord
- Découverte du machine learning et du rôle des data scientists
Pour s’assurer d’une bonne compréhension des concepts enseignés, les participant·e·s réalisent un projet en entreprise lié à la gestion ou la valorisation des données.



